Copyright © 2022-2025 aizws.net · 网站版本: v1.2.6·内部版本: v1.25.2·
页面加载耗时 0.00 毫秒·物理内存 94.2MB ·虚拟内存 1432.8MB
欢迎来到 AI 中文社区(简称 AI 中文社),这里是学习交流 AI 人工智能技术的中文社区。 为了更好的体验,本站推荐使用 Chrome 浏览器。
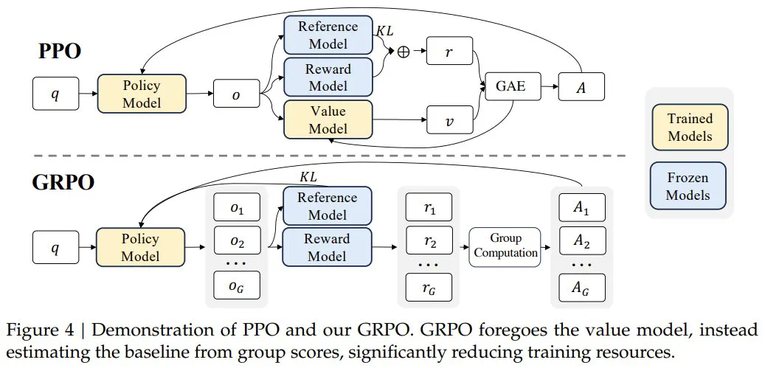



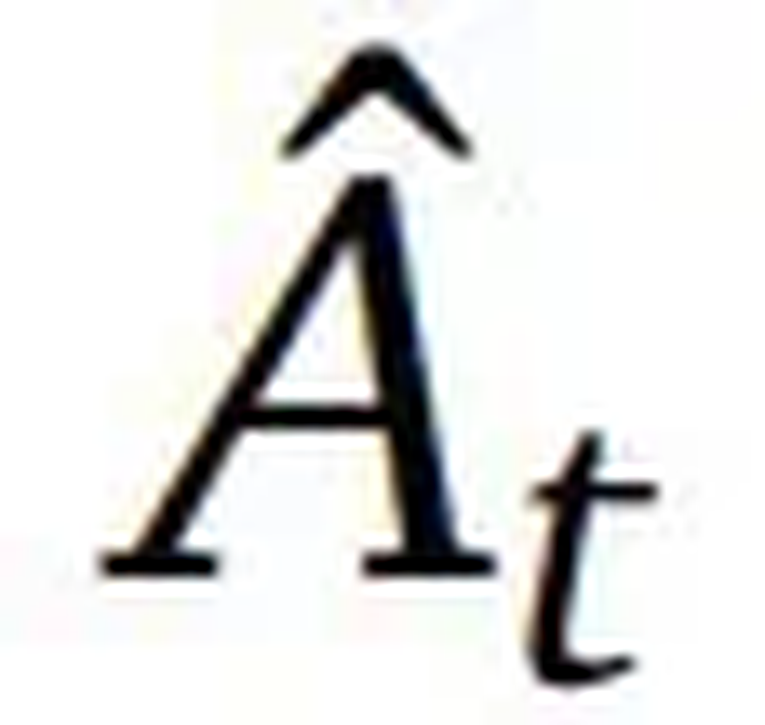 。一般来说,GAE 能在优势估计中提供偏差与方差的权衡,做法是通过一个由参数 λ 控制的指数加权平均值将 n 步优势估计组合起来。该优势估计的计算方式是:
。一般来说,GAE 能在优势估计中提供偏差与方差的权衡,做法是通过一个由参数 λ 控制的指数加权平均值将 n 步优势估计组合起来。该优势估计的计算方式是: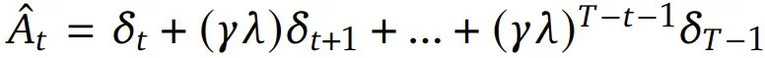 ,其中
,其中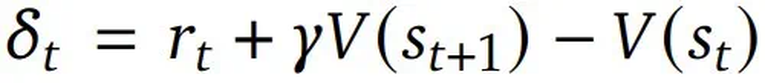 是 TD(temporal difference)残差,γ 是折扣因子,它决定了未来奖励相对于即时奖励的价值。该 PPO 算法通过优化以下目标函数来更新策略模型参数 θ 以最大化预期奖励和价值模型参数 Φ,从而最小化价值损失:
是 TD(temporal difference)残差,γ 是折扣因子,它决定了未来奖励相对于即时奖励的价值。该 PPO 算法通过优化以下目标函数来更新策略模型参数 θ 以最大化预期奖励和价值模型参数 Φ,从而最小化价值损失: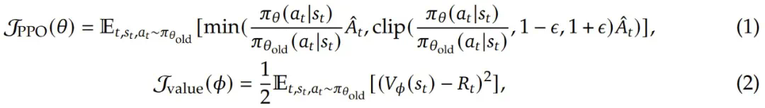
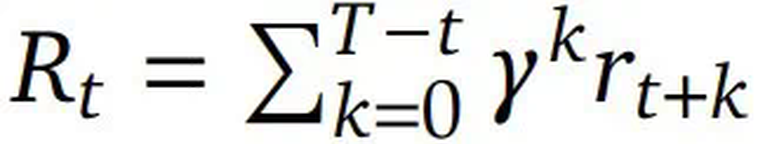 是折扣回报。
是折扣回报。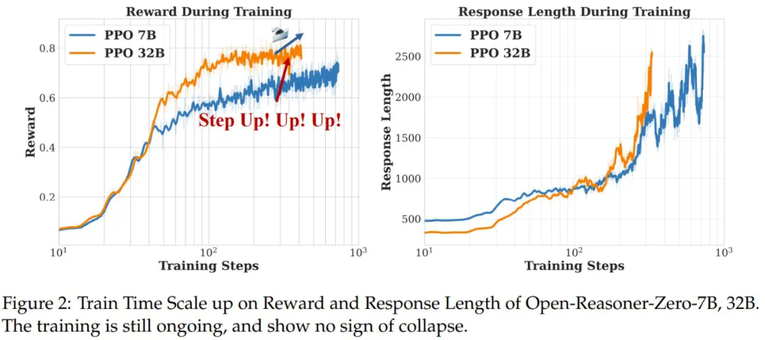
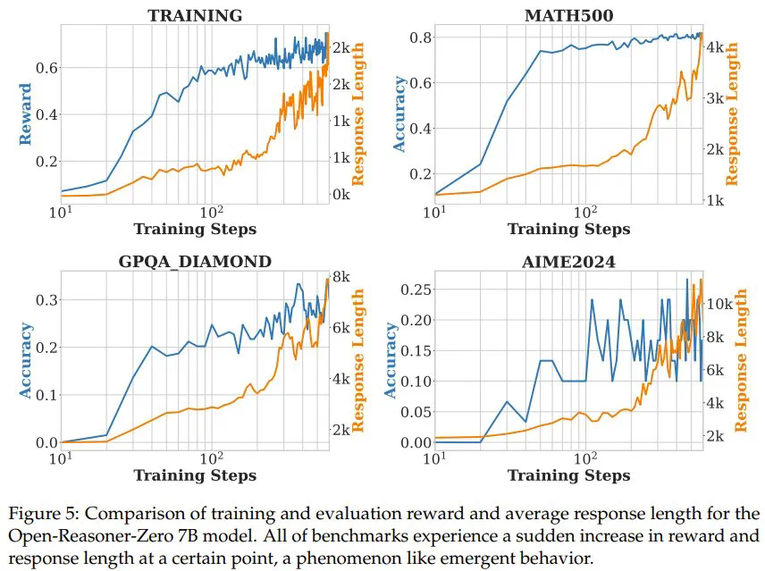
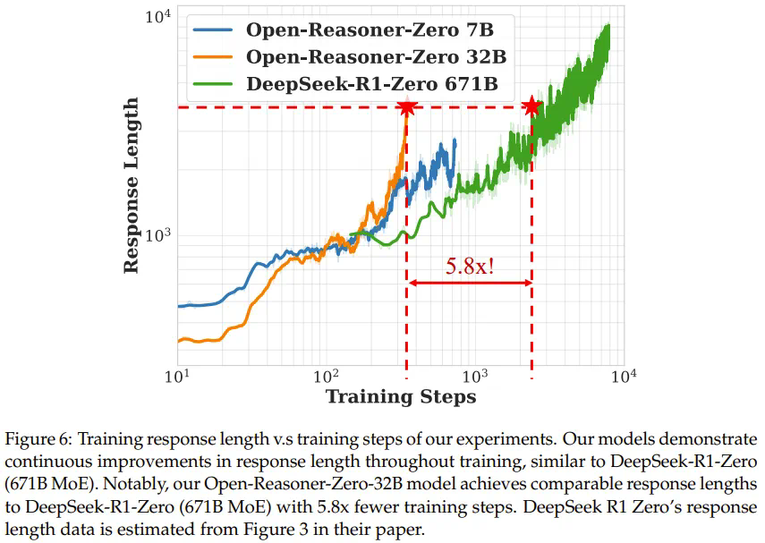
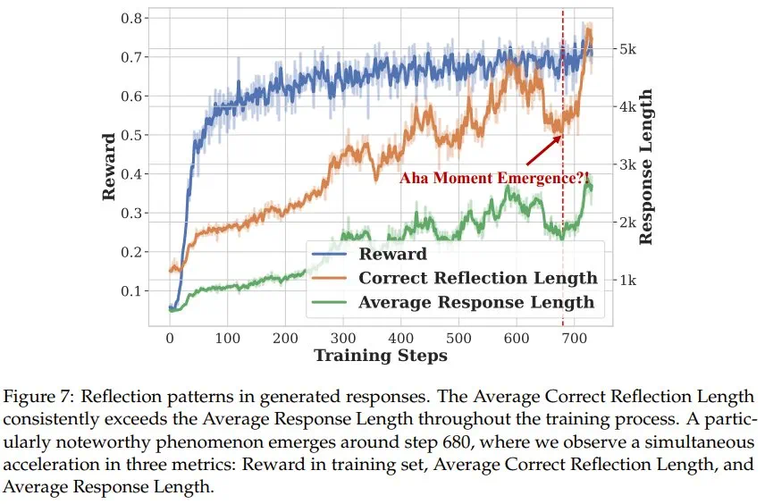
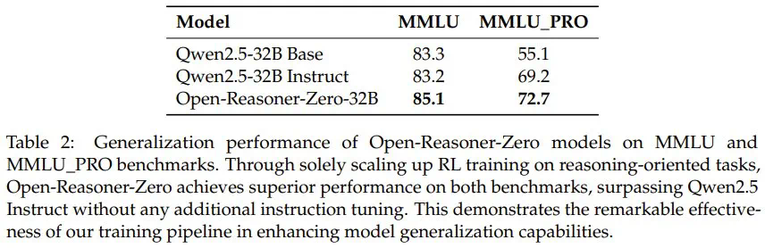
声明:本文转载自机器之心,转载目的在于传递更多信息,并不代表本社区赞同其观点和对其真实性负责,本文只提供参考并不构成任何建议,若有版权等问题,点击这里。